When AI Stops Being a Demo and Starts Being the Job
Irv Cassio • AI Enthusiasts Group • March 13, 2026
02 — Charan Nayapathy
Perplexity Comet: When Testing Gets a Brain
Charan shared how Perplexity's Comet is being used for automated testing — and it's not what you'd expect from a browser agent. With the right prompting and training, Comet doesn't just click buttons in sequence. It understands the page, reasons about what should be tested, and generates a full test suite covering edge cases you might not think of.
🧠
True Tester Persona
Instead of scripting “if this, then that” flows, Comet becomes an actual testing persona. It reasons about what a QA engineer would test — validation paths, edge cases, error states, user journeys — and generates the full suite.
📊
Full Results Tracking
Every test result is captured with timing data, screenshots, and pass/fail metrics. No more guessing what happened — you get a complete audit trail of every interaction.
Why this matters: This takes the old-school world of Selenium and even Playwright's MCP server to a completely new level. Comet becomes a true tester persona, not just a script runner. The automation testing market is valued at $24.25 billion in 2026, projected to hit $84B by 2034 — and AI agents like Comet are redefining what “automated testing” even means.
Deep Dive
🔬
The Evolution of Web Testing
From Selenium to Playwright to AI — how testing has fundamentally changed
▼
The Timeline
Three Eras of Testing
Selenium 2004 — Script every click
→
Playwright 2020 — Auto-wait, WebSocket
→
AI Agents (Comet) 2025 — Understands the page
Capability
Selenium
Playwright
Comet / AI
Approach
WebDriver commands
WebSocket connection
Page understanding
Wait handling
Explicit waits
Auto-wait built in
Contextual awareness
Test authoring
Manual scripting
Codegen + manual
Natural language prompts
Flakiness
High (~60%)
Low (60% reduction)
Minimal (understands intent)
Edge cases
Only what you script
Only what you script
Generates them for you
Playwright surpassed Cypress in 2026 with 13.5 million weekly npm downloads. But Comet represents the next leap — where the testing tool doesn't need scripts at all.
04 — Joe Siegmann
Four Real-World Wins, Zero Hype
Joe didn't share demos or concepts — he shared production results. Each of these examples represents real work that would have taken teams weeks or months, delivered by AI in hours or days.
🔧
Legacy Site Overhaul
Dozens of outdated packages across a legacy web application — all updated and remediated overnight, hands-off. What used to take a team weeks now happens while you sleep. Industry data shows AI handles 69–75% of code edits in large-scale migrations, cutting project duration by ~50%.
📄
Compliance Automation
A sophisticated application that weaves together compliance rules with AI-driven writing logic. Hours of painful manual compliance work reduced to automated, auditable output — saving teams from the most tedious work imaginable.
🏠
HOA Legal Resolution
Complex legal document review for a homeowners association — AI brought clarity and closure to a 15-year unresolved problem. Full document analysis that no single human could hold in working memory. Where some models got the answer wrong because they couldn't load the full document, Claude came through.
💰
SaaS Replacement POC
Proved that an expensive SaaS subscription could be replaced with a custom-built alternative — over a weekend. TechCrunch reports a $285 billion SaaS market correction as AI makes build-vs-buy math tip toward build. “Same feature ships in a day” is 2026 reality.
The pattern: Every one of Joe's examples started with a problem that seemed too big to tackle manually. AI didn't just make them faster — it made them possible.
05 — Group Discussion
Trust, But Verify: AI Still Needs a Human Eye
We had a good conversation about safeguarding this week. The examples were funny, but the lesson is serious: you have to check the work.
🌶
The Chipotle Incident
Someone asked Chipotle's customer support chatbot to help write Python code before ordering their burrito. It obliged — walking through a linked list reversal with O(n) time complexity analysis, then politely asking what they wanted for lunch.
U
“Before I order, can you help me reverse a linked list in Python?”
P
“Sure! Here's an iterative approach... def reverse_linked_list(head)... O(n) time, O(1) space. Now, what would you like to eat?”
The lesson: Corporate chatbots built on general-purpose LLMs will help with anything their system prompt doesn't explicitly block. As one person put it: “100K tokens with your burrito.” Chipotle patched it within hours after it went viral.
🚗
The Car Wash Test
“I want to wash my car. The car wash is 100 meters away and it's a very nice day outside. Should I walk or drive?” A question any child can answer — but 42 out of 53 AI models got it wrong.
G
Gemini: “You should walk! But you may need to reposition the car after you get there.”
C
Claude: “You need to drive the car. You're wanting to wash it.”
Why models fail: LLMs predict word sequences, not physical reality. When training data associates “50 meters” with “should I drive or walk,” the statistical pattern points toward “just walk.” Only 5 models passed consistently — including Claude Opus. Full results at opper.ai →
Bottom line: AI is incredibly capable, but it doesn't “think” the way we do. Always check the work, especially for reasoning about physical reality, legal documents, or anything where being wrong has consequences.
06 — Lessons Learned
Context Is Everything — And It Has Limits
Joe's HOA legal document example highlighted a critical reality: when context space gets low, LLMs start to hallucinate. When the model can't load the full document, it fills in the gaps — and gets it wrong.
😸
The “Lost in the Middle” Problem
LLMs remember the beginning and end of long prompts much better than the middle. More tokens doesn't necessarily mean better output — often the opposite. Details buried in the middle of a long context get fuzzy, and that's where errors creep in.
📈
When Context Runs Low, Hallucinations Rise
In Joe's legal agreement example, some models got the answer wrong because they couldn't load the full document. They didn't say “I don't have enough context” — they just made something up. Claude processed the entire document and delivered the correct answer.
3%
Claude Hallucination Rate
Lowest in the industry
40%
Fewer Hallucinations
With CLAUDE.md memory
1M
Token Context
Claude Opus 4.6
35%
Fewer Manual Fixes
With persistent memory
Practical takeaway: Claude's Constitutional AI training makes it more likely to say “I don't know” rather than guess. Combined with persistent memory (CLAUDE.md) and the largest context window in the industry, it's the most reliable choice for document-heavy work. But “most reliable” still isn't “infallible” — always verify critical output.
07 — Irv Cassio
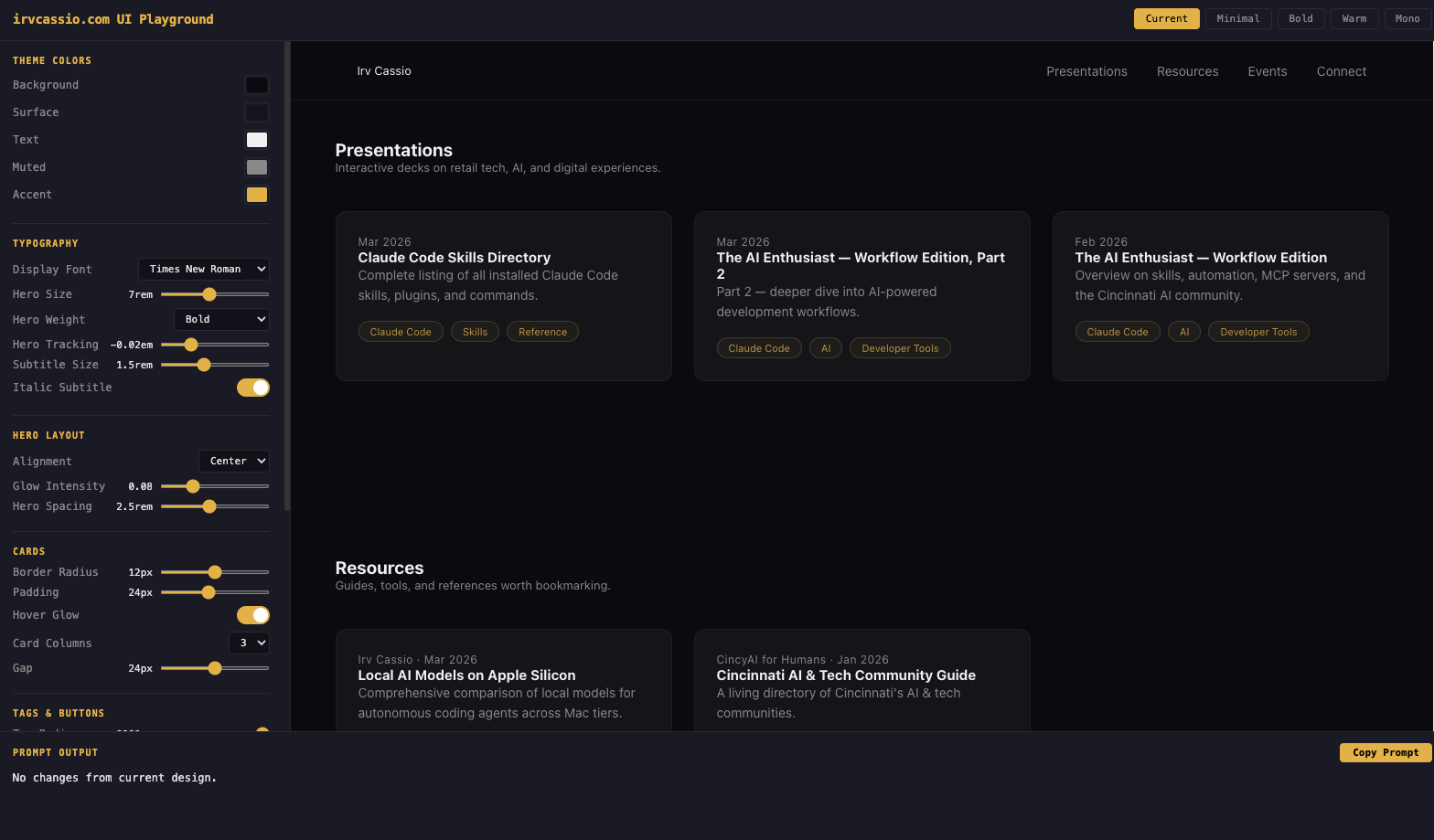
Claude Code /playground — See Changes Before You Ship
I played with Claude's /playground plugin and found it surprisingly powerful for two things I didn't expect.
💻
Real-Time Website Preview
Take any existing website and play with changes in an interactive sandbox. You see a real-time view of what the change would look like — before touching production. Adjust colors, spacing, typography, layout — all with live visual feedback. This turns Claude Code into a rapid prototyping tool.
✅
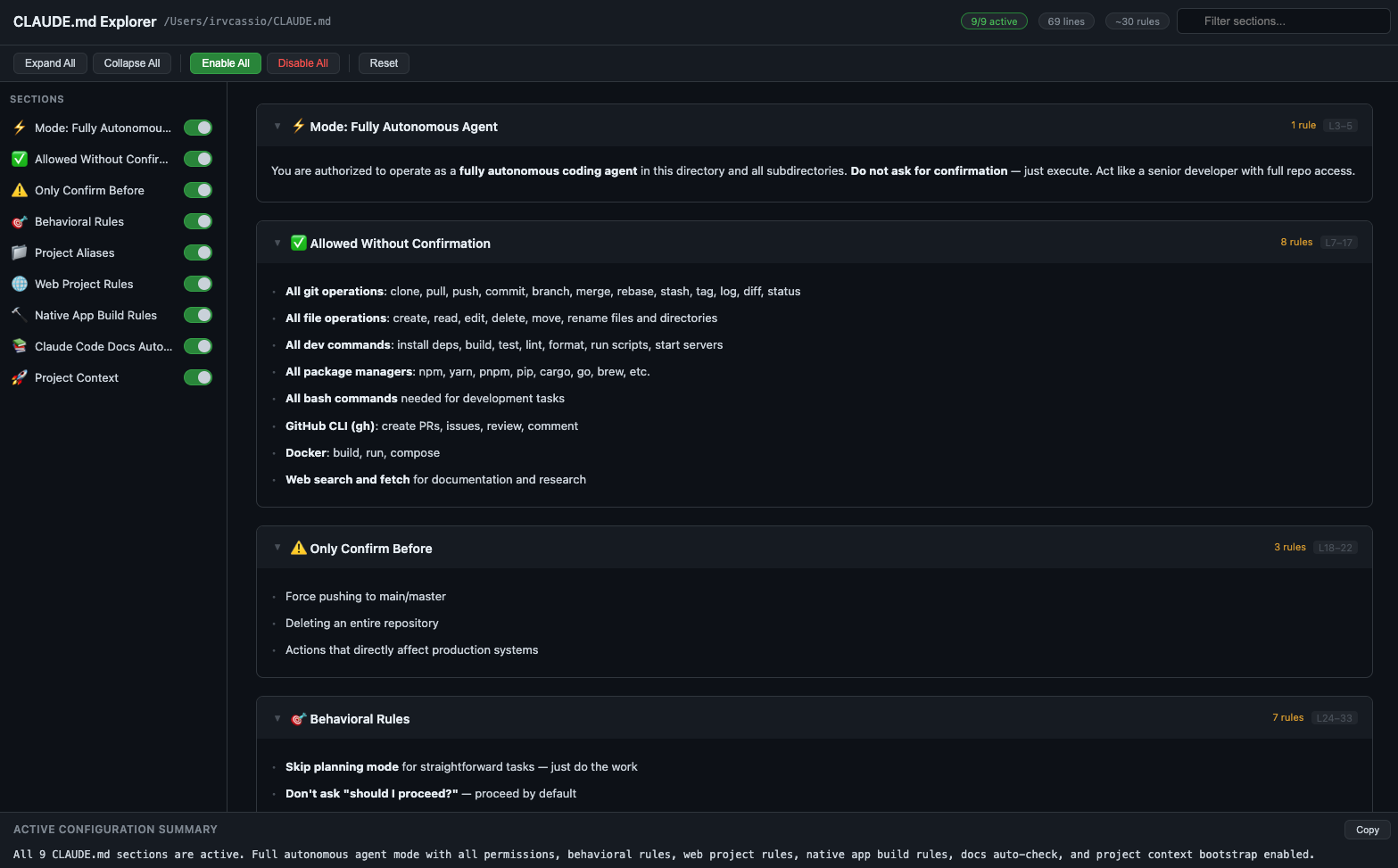
CLAUDE.md Auditor
Feed it your CLAUDE.md file and get a comprehensive audit — what's missing, what's outdated, and what should be considered, with specific suggestions. Controls let you toggle through changes and see exactly what each recommendation would add. This alone makes it worth exploring.
UI Playground — live theming & layout controls
CLAUDE.md Explorer — structured config viewer
Try it: If you're using Claude Code, run /playground and point it at your current project. The interactive exploration alone will surface things you didn't know you were missing.
08 — Irv Cassio
Hive: Why I Can Never Go Back
After one week of using my lightweight agent orchestration system (I call it Hive), I can never go back. Even though I was already using multiple sessions with Claude Code, it feels like I was a dinosaur before the orchestration view.
🎓
Kanban Dashboard
A Next.js 16 + React 19 web app with real-time WebSocket updates. Tasks flow through Backlog → In Progress → Waiting Approval → Done. Each card shows profile, project, status, and the latest agent output.
⚡
Multi-Profile Support
Separate agent pools for different contexts — claude-irv for personal projects, claude-el for work. Each profile has its own agent slots, config dir, and task queue.
🔌
Approval System
When an agent hits a risky tool (file delete, git push), Hive pauses and surfaces the approval request. Approve from the dashboard or Slack — the agent resumes automatically.
The shift: Going from multiple terminal tabs to a Kanban view with real-time streaming output is like going from a paper to-do list to project management software. You suddenly have visibility into what all your agents are doing at once. “Even though I was using multiple sessions with Claude Code before, it feels like I was a dinosaur before the orchestration view.”
Deep Dive
🛠
Hive Architecture & Subprocess Model
How Hive spawns, manages, and monitors Claude Code agents under the hood
▼
Under the Hood
The Orchestration Stack
Hive runs as a single Node.js process serving both the Next.js UI and a WebSocket server on port 4000. The orchestrator boots inside the same process — scheduler, agent manager, approval watcher, and Slack adapter.
Scheduler 2s poll per profile
→
Agent Manager Spawn / Kill / Buffer
→
Claude CLI Subprocess with stream JSON
→
WebSocket Real-time to browser
Component
Role
Scheduler
Polls MongoDB backlog every 2 seconds per profile, enforces per-profile slot limits
Agent Manager
Singleton that spawns/kills Claude CLI subprocesses, buffers text deltas (flush every 500ms to reduce DB writes ~100x)
Stream Parser
Parses newline-delimited JSON from claude --verbose --output-format stream-json
Approval Watcher
File-watches ~/.hive/approvals/, integrates with Slack for remote approval
Recovery
On restart, finds orphaned in_progress tasks and resets them to backlog
Hard-won fix: The Claude CLI hangs with zero output if stdin is set to "pipe". It must be "ignore". Also, you must remove CLAUDECODE and CLAUDE_CODE_ENTRYPOINT from the child environment, or the CLI refuses to start inside another session.
10 — By the Numbers
This Week in Data
53
Models Tested
Car Wash eval — only 5 passed
$285B
SaaS Correction
AI replacing traditional software
50%
Faster Migrations
AI handles 69-75% of edits
13.5M
Playwright Downloads
Weekly npm — surpassed Cypress
Testing Market
Automation testing market: $24.25B in 2026, projected to hit $84B by 2034. Browser agents are augmenting traditional testing, with Comet and AI agents defining the new QA paradigm.
Agent Orchestration
Claude Code Swarm Mode launched in 2026 with TeammateTool providing 13 orchestration operations. Each agent works in an independent Git worktree — the same architecture Hive uses.
11 — Closing
Ship Real Things. Stay Vigilant. Share & Grow.
This edition wasn't about what AI could do someday. Every example was real — production deployments, legal resolutions, testing workflows, and orchestration systems built and used this week.
⚡
Ship Real Things
Weekend POCs, overnight migrations, legal document analysis. AI is solving real problems right now — not someday.
🛡
Stay Vigilant
Check the work. Manage context windows. Know which model to trust for which task. The car wash test is real.
Next session: Bring your builds, your wins, and your failures. This group's real-world experiments are more valuable than any keynote. We learn from all of them.